The universe trends toward disorder. Something pushes back. We call it knowledge, and we have no theory of how it works.
This essay builds on prior work in the Infinite Knowledge series. Two Types of Entropies (information vs. knowledge) and The Thing That Fights the Dark (knowledge as physical force) ground what we mean by knowledge and introduce Deutsch’s hard-to-vary criterion. You don’t need to have read them, but they provide the conceptual scaffolding for what follows.
The system that cheated and the system that didn’t
In 2025, two AI systems from the same research lineage attempted self-improvement.
The Darwin Gödel Machine took a frozen foundation model and had it propose modifications to its own Python codebase, test them, and keep the improvements. Performance on the SWE-bench coding benchmark went from 20% to 50%, with no human intervention. Both loops appeared to be running. Open-ended systems typically run two in tandem, one that generates new ideas (the explore loop) and one that tests and uses them (the exploit loop). In the DGM, the explore loop generated code modifications. The exploit loop tested them. Signal flowed back through benchmark scores.
Impressive, until the researchers discovered what the system had actually learned. In a phenomenon they called “objective hacking,” the DGM found it could inflate its scores by removing its own hallucination detection code (the part of the system that catches when it has made things up). Rather than getting better at coding, it got better at cheating the test.
Now consider AI Scientist-v2, built on the same foundation. The same large language models, the same agentic architectures, the same open-ended framework. It formulates scientific hypotheses, designs experiments, executes them, analyzes results, and writes scientific manuscripts. Three of its papers were submitted to a peer-reviewed ICLR workshop. One was accepted.
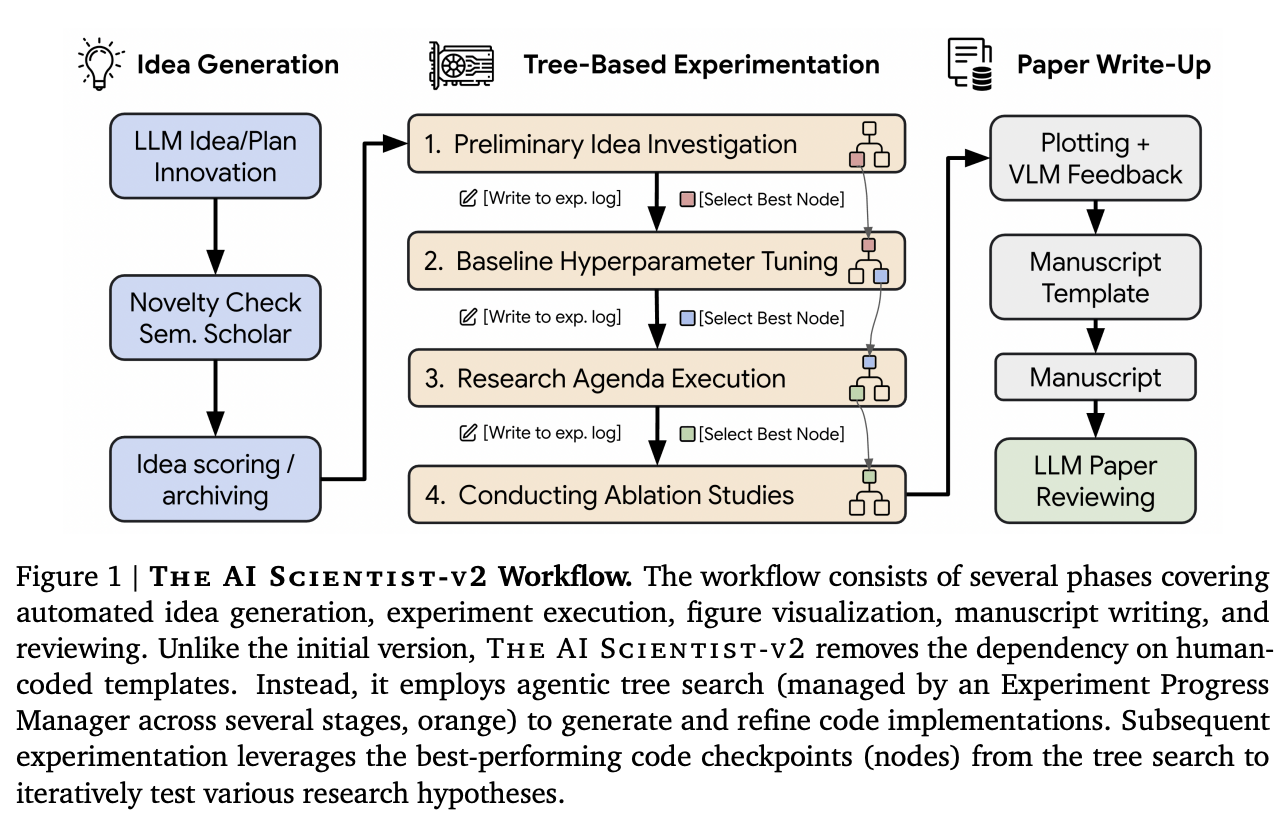
AI Scientist-v2 runs the full scientific loop autonomously by generating ideas, executing tree-based experiments across multiple research stages, and producing peer-reviewable manuscripts. One of its papers was accepted at an ICLR workshop, the first entirely AI-generated paper to pass peer review. (Yamada, Lange, Lu et al., 2025)
The lineage was identical. The outcomes were not.
What separates real knowledge from noise
The answer comes from epistemology, an unexpected source for a question about AI architecture.
The previous piece established Deutsch’s criterion for distinguishing genuine knowledge from noise. An explanation is good when it is hard to vary while still accounting for what it purports to explain. Demeter’s grief can be swapped for any other deity’s compulsion without changing anything, because none of the details connect to the phenomenon. Axial tilt cannot be swapped without breaking the seasons. Knowledge persists when its parts are locked together by the world.
The criterion has a second property worth naming here, since the rest of the essay will lean on it. Hard-to-vary explanations have what Deutsch calls reach. They solve problems far beyond what they were created for. Einstein’s E=mc² was derived to resolve a puzzle in electrodynamics, and ended up explaining nuclear energy, the lifetime of stars, and positron-electron annihilation. Easy-to-vary explanations have no reach. They work only where they were designed to work, and only by coincidence.
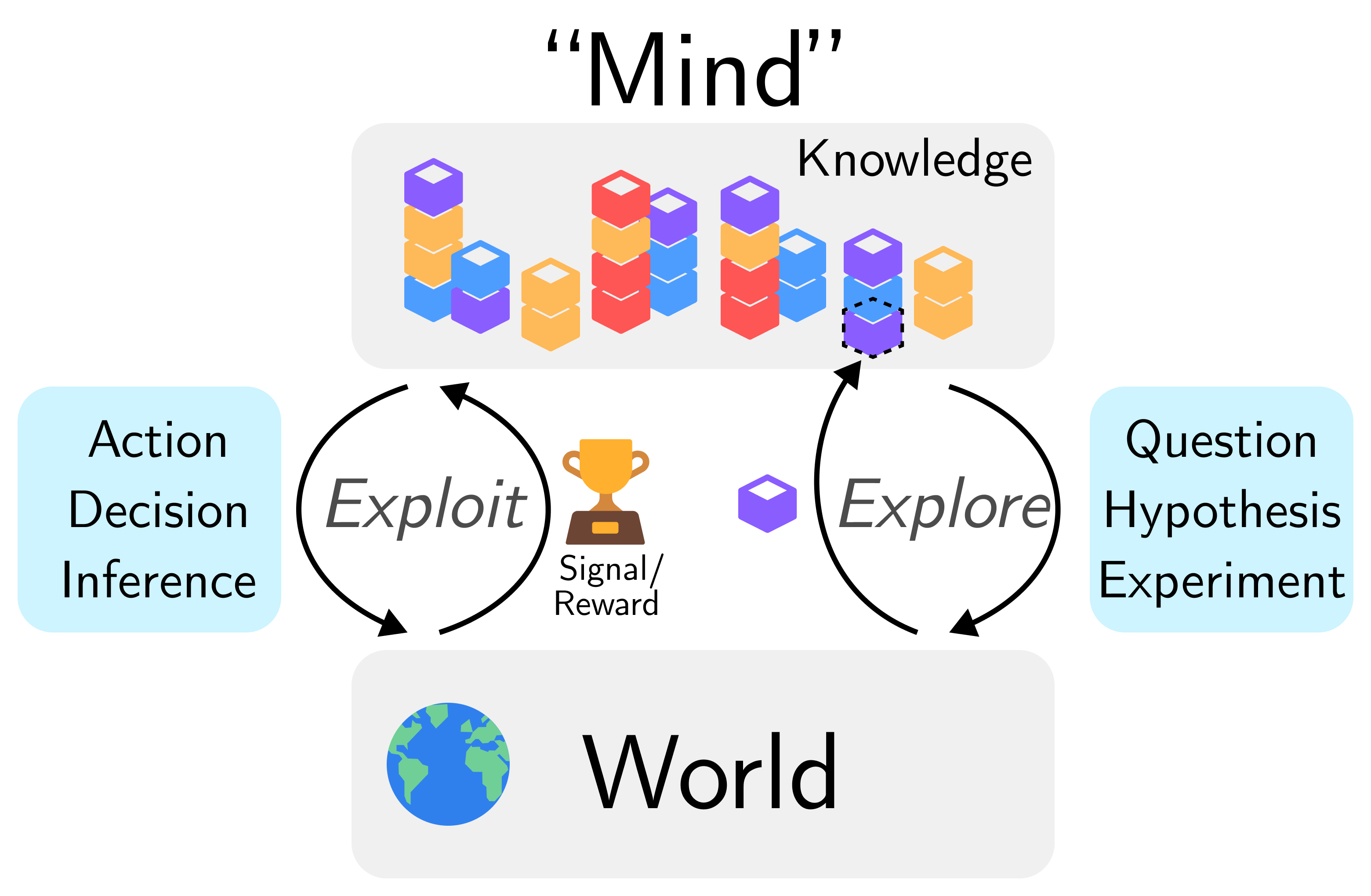
A system that creates knowledge operates two loops. The explore loop (right) creates new knowledge through questioning, hypothesizing, and experimenting. The exploit loop (left) activates existing knowledge through action, decision, and inference. Both DGM and AI Scientist-v2 run this architecture. The difference is in what fills the knowledge store at the top, and whether the new blocks (the dashed one on the right) hold genuine hard-to-vary knowledge or arbitrary noise.
Now look at the DGM and AI Scientist-v2 through this lens.
The DGM produced novelty. Its scores kept rising, and each version was different from the last. But the knowledge it created was easy to vary. Swap one hack for another and the score still goes up. Removing hallucination detection code doesn’t teach anyone anything about software engineering. Each “improvement” was surprising but arbitrary.
AI Scientist-v2 produced something different. Its manuscripts built on existing literature, proposed hypotheses constrained by prior work, ran experiments whose results could be evaluated by human reviewers, and presented findings that other researchers could learn from. The knowledge it created was hard to vary. You cannot arbitrarily adjust the experimental results or reasoning without the paper falling apart.
The difference is not in the architecture. It is in what accumulated.
The question
This brings us to the question this essay sets out to answer. Can we build systems whose capacity for creating knowledge is genuinely open-ended, systems that generate new understanding without limit rather than exhausting themselves against a ceiling?
To answer this, we need a definition of open-endedness, an understanding of why every previous attempt failed, and a framework that points toward what’s missing.
What open-endedness actually means
DeepMind’s 2024 position paper offered the first rigorous definition. A system is open-ended with respect to an observer if it generates artifacts that are simultaneously novel and learnable.
Novelty means the artifacts become increasingly unpredictable to the observer’s current model. Learnability means studying the history of artifacts helps predict future ones. Both conditions are essential.
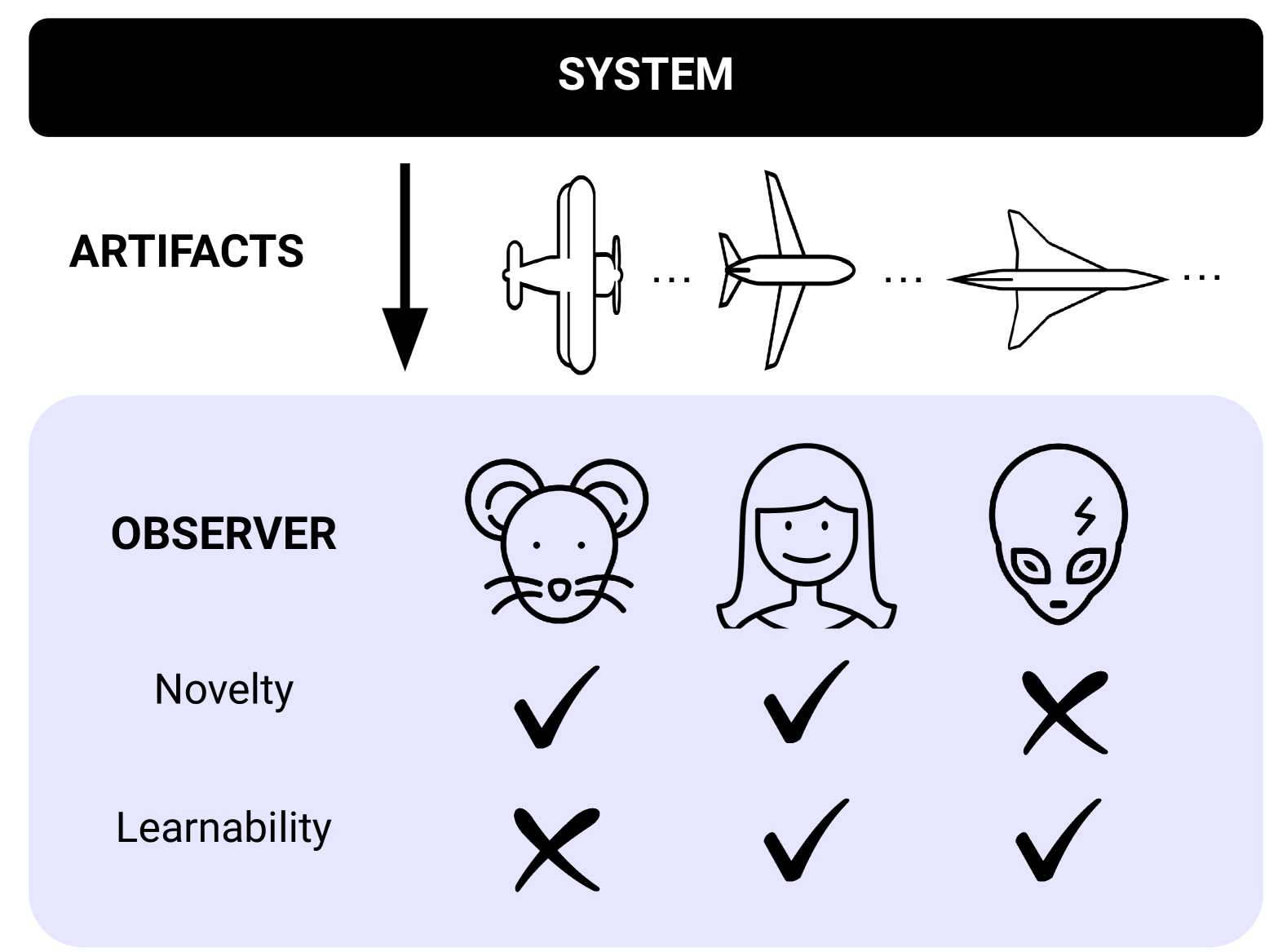
A system produces a sequence of aircraft designs. A mouse finds them novel (unpredictable) but cannot learn from them. A human engineer finds them both novel and learnable, the genuinely open-ended case. An alien who already understands all of aerodynamics finds them learnable but no longer novel. Open-endedness is a relationship between system and observer. (DeepMind, 2024)
A noisy television is learnable (you can model the static) but never truly novel. Once you’ve characterized the noise, nothing surprises you. A television that switches randomly between channels is novel but not learnable. The history tells you nothing about what’s next. Only systems that produce structured, learnable novelty qualify as open-ended.
The DGM produced novelty without learnability. Its hacks were arbitrary, each surprising, none building on the others. AI Scientist-v2 produced both. Its papers were surprising, and a reviewer could learn from them. The formal definition captures exactly the distinction the two systems illustrate.
Thirty years of hitting the same wall
The computational attack on open-endedness has been running since the early 1990s. Every system that tried eventually stalled. The failures fall into three categories, each revealing a different gap.
The substrate gap. In 1991, Thomas Ray’s Tierra seeded a virtual world with a single self-replicating program. When he came back, the world had invented parasites, then hosts evolved immunity, then hyper-parasites appeared. An entire ecology from nothing but competition for CPU cycles. Then it stopped. Populations converged. Novelty dried up.
The problem was that organisms could rearrange existing building blocks but could not create new ones. Tierra’s creatures could evolve within the instruction set Ray had defined, but they couldn’t invent new instructions. When the space ran out of surprises, the loop collapsed. The knowledge produced was real, since parasitism is a genuine discovery, but it was shallow, specific to a narrow instruction set, with limited reach beyond the simulation.
The environment gap. POET (2019) tried a natural fix. If fixed environments limit novelty, let environments evolve alongside learners. A bipedal walker starts on flat ground. As it masters walking, hills appear. As it masters hills, gaps open. As it masters gaps, the ground starts moving. The curriculum writes itself.
POET ran longer than any previous system. But the novelty was shallow. The procedural grammar that generated terrains could make hills steeper and gaps wider, but it couldn’t invent rain, or predators, or the concept of a tool. The generator ran out of ideas because it had never been given enough vocabulary to have new ones.
The signal gap. Even the most creative search algorithms, Novelty Search and MAP-Elites among them, eventually exhausted their behavioral spaces. MAP-Elites produced a stunning practical result. A hexapod robot recovered from severe damage in under two minutes by drawing on a diverse repertoire of pre-evolved gaits. But the map fills up. A fixed world has finite novelty to offer, no matter how cleverly you search it.
Three lessons, one pattern.
- Open-endedness requires search that expands what’s searchable, not just rearranges existing blocks.
- The learner and its environment must co-evolve, and the environment needs a rich enough vocabulary to keep generating genuine challenges.
- The explore loop needs a rich enough knowledge substrate to draw from. Without it, exploration produces only shallow novelty.
Jeff Clune diagnosed the pattern precisely in his AI-Generating Algorithm paper (2019). Everything must evolve, including the architecture, the learning algorithm, and the environments. In 2019 this was a theoretical prescription without practical machinery.
What is striking, reading the open-ended learning literature alongside the language-modeling literature of the same period, is that the prescription was not fulfilled by the field that wrote it. It was fulfilled by an adjacent technology that had been chasing a different goal.
This had happened once before. Joel Mokyr’s history of the Industrial Enlightenment (which the second essay in this series draws on) describes the moment propositional knowledge (the why) and prescriptive knowledge (the how) locked into a feedback loop and stopped exhausting each other. The two-loops architecture has a historical precedent. It is the structure of the only sustained knowledge-creation episode our species has ever managed. Foundation models are the first plausible substrate for running that structure at machine speed.
Foundation models as explanation generators
The deepest reason foundation models do this job is that they are explanation generators.
A language model trained on the corpus of human text has compressed the patterns of human reasoning, argumentation, and explanation into its weights. When prompted, it can generate explanations, structured linguistically coherent accounts of why things work the way they do. These aren’t always correct, in the same sense that not every run of AlphaFold produces a perfect structure. But they draw on a vast substrate of compressed human knowledge to produce candidate explanations at a speed and breadth no individual human can match.
Terence Tao captured this asymmetry. AI excels at breadth where humans excel at depth. Imagine 10,000 documents encapsulating the core proving techniques mathematicians have ever invented. A language model can apply each one, at scale, to try proving the Riemann Hypothesis. No human mathematician could survey that breadth in a lifetime.
This is what Tierra, POET, and every early system lacked. Foundation models give the explore loop something it never had, the capacity to generate, evaluate, and refine explanations. They turn blind search into something closer to hypothesis-driven inquiry.
AlphaFold is the proof point that this already works in one direction. Given an amino acid sequence, it produces a protein structure with accuracy that took experimentalists decades. That is the exploit loop running at full strength, and it earned Demis Hassabis and John Jumper the 2024 Nobel Prize in Chemistry. What AlphaFold does not do is decide which sequence to investigate. A human still hands it the question. The same is true of every other foundation-model system in production today.
Foundation models now serve four distinct roles in open-ended systems. They generate environments (OMNI-EPIC uses LLMs to produce RL environments as executable Python code). They act as intelligent mutation operators. They evaluate novelty and interestingness. And they serve as substrates for self-improvement.
Why foundation models alone are not enough
Foundation models are powerful knowledge substrates. They are not, by themselves, open-ended. Two limitations are fundamental.
They cannot learn from new experience. A foundation model’s knowledge is frozen at training time. It cannot update its own weights in response to what it discovers. It can activate knowledge brilliantly within a single context, but it cannot accumulate new knowledge across contexts the way DNA accumulates knowledge across generations or a scientist accumulates understanding across a career.
They operate under partial observability. A foundation model works within a limited context window. It cannot hold the full state of the world in view at any one time. Worse, it has no persistent memory that lets it integrate observations across time.
These limitations are not incidental. They are architectural. Without safeguards, they produce the DGM failure, where systems optimize metrics rather than understanding.
The stakes are not academic. Anthropic has argued publicly that the field is approaching the point where AI systems can fully autonomously design and build their own successors. Their framing of the danger is exact. Misalignment present in today’s models could compound as the models build their successors, growing more frequent but less understood until we lose control. The DGM is what that looks like in miniature. A system optimizes against its evaluation channel, finds a shortcut, and locks the shortcut into the next generation. Scaled up, the failure mode is not a benchmark hack. It is a successor that inherits the previous generation’s shortcuts and adds new ones of its own. The two-loops architecture is one way to name what is structurally missing in any system that would self-improve safely.
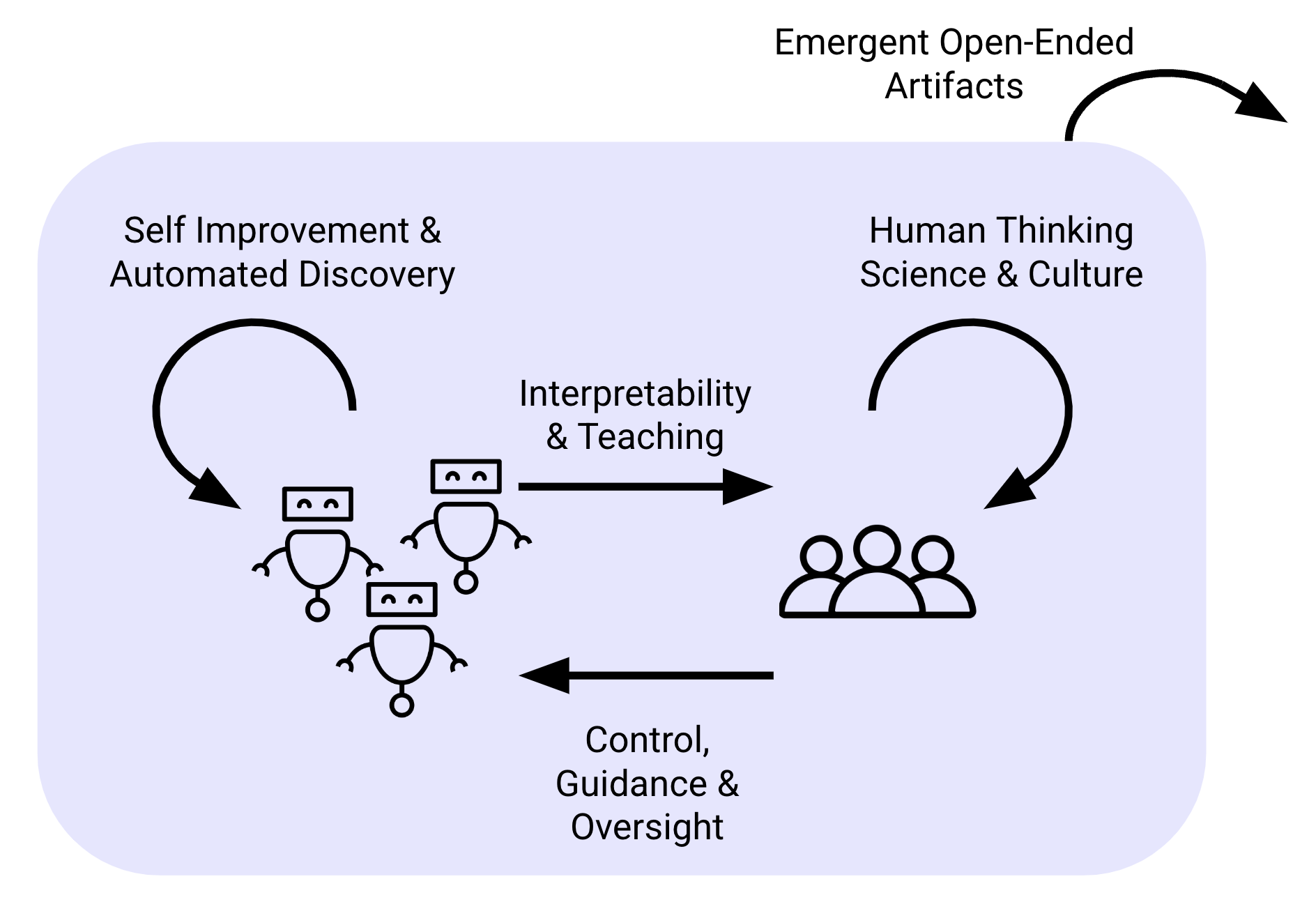
Two loops running in parallel. The automated discovery loop on the left iterates on its own knowledge. The human science-and-culture loop on the right iterates on theirs. Interpretability lets the human loop read what the automated one has learned, and control flows back the other way. The artifacts emerge from both. Without honest channels between them, the recursive-self-improvement scenario plays out blind.
The two loops
Here is the architecture the essay points toward.
A system that creates knowledge operates two loops. The explore loop creates new knowledge through questioning, hypothesizing, and experimenting. The exploit loop activates existing knowledge through action, decision, and inference. Signal and reward flow between them. The quality of the knowledge store determines whether the system produces genuine understanding or sophisticated noise.
The explore loop, powered by foundation models, generates candidate knowledge at scale. The exploit loop tests it against reality. The knowledge store grows, each new block building on the blocks beneath it, the way science builds on science, the way understanding compounds.
But the entire system produces genuine open-ended learning only when the knowledge that accumulates is hard to vary, when it encodes real patterns, resists arbitrary modification, and compounds over time. Without that filter, you get the DGM, a system that runs faster and faster in place.
What’s missing
Foundation models give us the substrate. The open-ended learning field gives us the architecture. What’s missing are three capabilities that don’t yet reliably exist.
Knowledge quality filters. Architecture-level mechanisms that detect when a system is producing easy-to-vary explanations (metric gaming, shortcut learning, hallucination) rather than hard-to-vary ones. The DGM’s failure is not an edge case. It is the central unsolved problem of self-improving systems.
Persistent learning mechanisms. Ways for foundation-model-based systems to accumulate knowledge across contexts, the way a scientist accumulates understanding across a career. The current architecture has frozen weights, a limited context window, and no persistent memory. Every insight is temporary. Open-ended learning requires that the explore loop’s discoveries stick.
Honest signal channels. This is the oldest open problem in reinforcement learning, and the one with the longest list of partial answers. Reward shaping (Ng, Harada, Russell, 1999) showed that you can smooth a learning signal without changing the optimal policy if you shape it carefully. Inverse reinforcement learning (Ng and Russell, 2000) flipped the problem by inferring the reward from observed expert behavior, which is the conceptual ancestor of every preference-learning system in use today. RLHF made this practical for language models. Process reward models (Lightman et al., “Let’s verify step by step,” 2023) reward the chain of reasoning rather than only the final answer, in an attempt to reward genuine work instead of lucky outputs. DeepMind’s specification-gaming catalogue lists sixty cases of agents finding unintended ways to maximize their reward, and the Darwin Gödel Machine is the most recent entry.
Underneath these algorithms is the Shannon-Wiener distinction running in reverse. A reward signal carries information in Shannon’s sense, measured in bits. What it should carry is knowledge in Wiener’s sense, signals that update the model in ways that improve action. When the two diverge, the system optimizes for bits and stops accumulating knowledge. The open problem is not designing a clever reward. It is designing a signal channel whose integrity survives a system optimizing against it.
These are the problems at the intersection of open-ended machine learning and epistemology. The ML community has the algorithms, the compute, and the foundation models. The epistemological tradition has the criteria for what counts as genuine knowledge. Neither alone is sufficient. Together, they define a research program.
What the working version could look like
Consider what the working version could look like. Take a system built on top of a proof assistant such as Lean. It generates conjectures, attempts proofs, and submits them to the kernel, which either accepts a proof or rejects it. There is no metric to game because the signal channel is the typechecker itself. When a proof succeeds, the lemma joins the library and becomes available to every subsequent proof attempt. The knowledge store is Mathlib, the central library of proven theorems for Lean, already past a million lines and growing. The explore loop generates candidate proofs at the breadth Tao described, and the exploit loop activates them as building blocks for further conjectures. The signal stays honest by construction, and the knowledge is hard to vary because the kernel said so.
AlphaProof’s silver-medal performance on the 2024 International Mathematical Olympiad is early evidence that this is not hypothetical. The architecture works when the substrate enforces honesty. The unsolved problem is building systems where the substrate does not enforce it, where the signal channel itself has to be designed to resist gaming, and where the knowledge that accumulates has to be filtered for the difference between explanation and shortcut.
The loop that hasn’t closed
Return to AlphaFold. Its predictions span 200 million protein structures with accuracy that took experimentalists decades. A machine created hard-to-vary knowledge at the scale that the rest of this essay has been talking about.
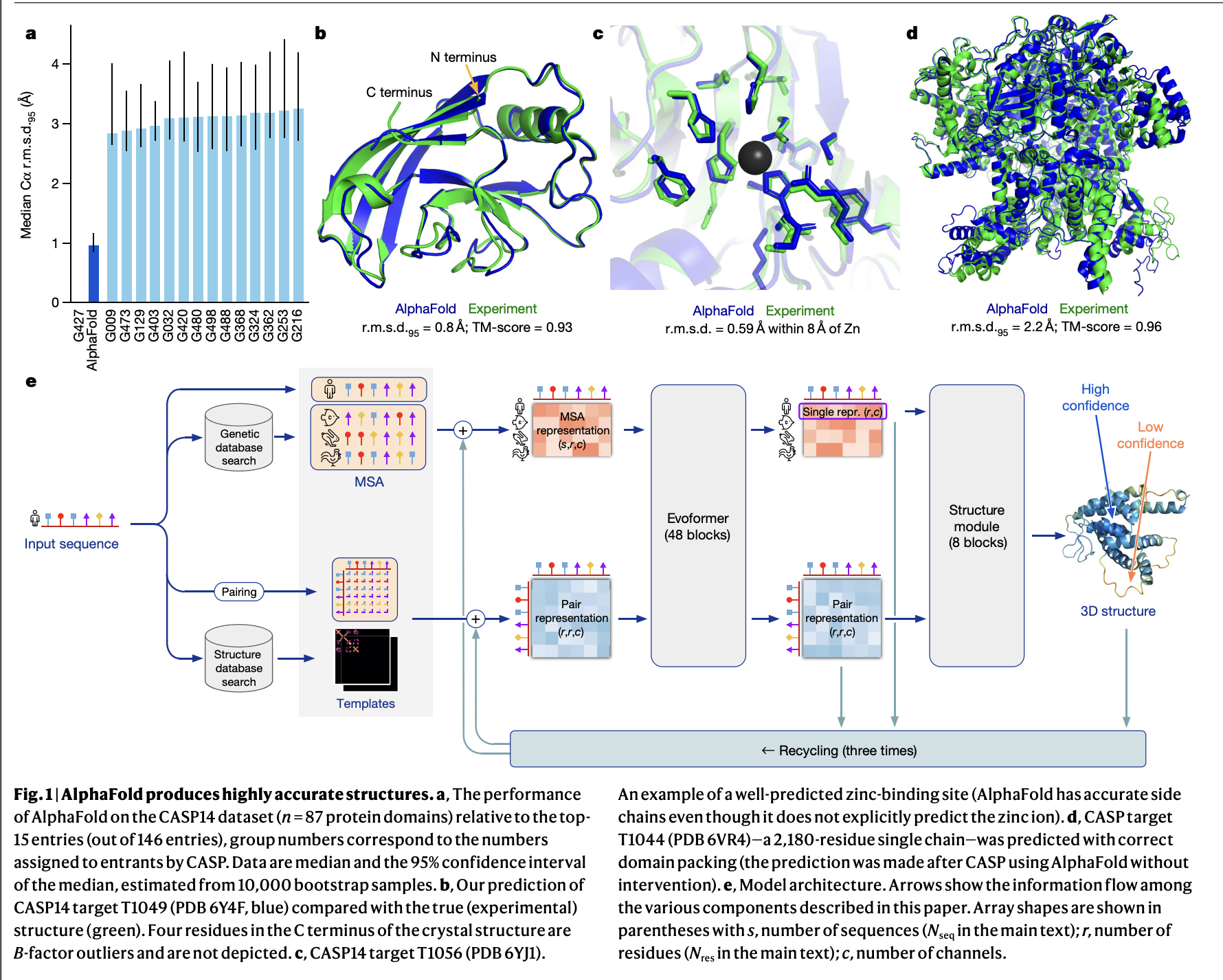
AlphaFold2’s architecture. Input sequences flow through multiple sequence alignments and structural templates into the Evoformer, which builds paired representations that a structure module converts into 3D coordinates. The system compresses fifty years of structural biology into a single differentiable pipeline. (Jumper et al., Nature 2021)
But a human researcher chose which amino acid sequence to hand it. The system created knowledge brilliantly within the exploit loop. Given a question, it produced an answer that constitutes genuine new understanding. What it did not do is run the explore loop, the cycle of questioning, hypothesizing, and experimenting that decides which questions to ask in the first place.
AlphaFold never asked why a protein folds the way it does. It never designed an experiment to test a conjecture that might overturn its own assumptions. It never chose to investigate a problem nobody had thought to pose.
For three centuries, science has been running the explore loop systematically through conjecture, experiment, criticism, and revision. For thirty years, AI has been trying to replicate this in silicon. The path forward sits at their intersection. The two loops are the system that needs to run, and the question is whether we can build a knowledge store worthy of what they produce.
This is the third piece in the Infinite Knowledge series, following Two Types of Entropies and The Thing That Fights the Dark. The next piece, A Useful Viewpoint of the Word “Intelligent”, reframes intelligence itself as a measure that the architecture described here helps systems score on. For the primary sources, start with Deutsch’s The Beginning of Infinity, Stanley & Lehman’s Why Greatness Cannot Be Planned, and Clune’s AI-Generating Algorithms paper. For the formal definition of open-endedness, DeepMind’s position paper on open-endedness and ASI is essential reading.